2017. 3. 18. 08:13 devel/android
안드로이드 센서 프레임워크 분석#2 - Android Sensor Service Porting
Sensor Stack
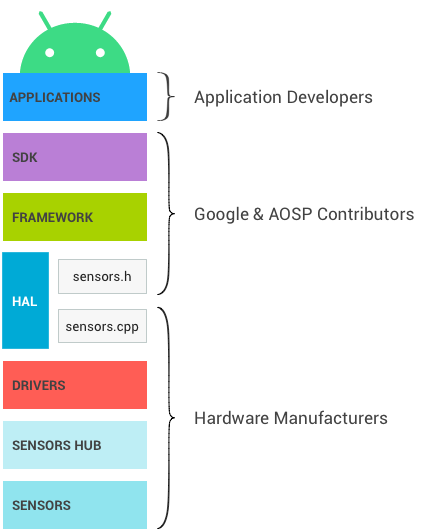
출처 : https://source.android.com/devices/sensors/index.html
이번에는 HAL에서 framework로 어떻게 올라가는지 확인해보려 한다
framework에서 HAL을 어떻게 호출?
이 파일에는 볼게 많다. 실제 휴대폰에 adb로 들어가서 /system/lib/hw 디렉토리에 뭐가 있나 봐보자
hardware/libhardware/hardware.c
int hw_get_module_by_class(const char *class_id, const char *inst,
const struct hw_module_t **module)
{
...
return load(classid_, path, module);
}
int hw_get_module(const char *id, const struct hw_module_t **module)
{
return hw_get_module_by_class(id, NULL, module);
}
#define HAL_MODULE_INFO_SYM HMI
#define HAL_MODULE_INFO_SYM_AS_STR "HMI"
static int load(const char *id,
const char *path,
const struct hw_module_t **pHmi)
{
...
void *handle = dlopen(path, RTLD_NOW);
/* Get the address of the struct hal_module_info */
const char *sym = HAL_MODULE_INFO_SYM_AS_STR;
struct hw_module_t *hmi = (struct hw_module_t *)dlsym(handle, sym);
if(hmi->dso)
hmi->dso = handle;
*pHmi = hmi;
...
}
네 그렇습니다. load라는 녀석을 통해 심볼 호출이 되어 HMI가 읽힙니다
hw_get_module_by_class 같은 함수는 밑의 SensorDevice.cpp에서 호출이 됩니다
hardware/libhardware/include/hardware/sensors.h
static inline int sensors_open_1(const struct hw_module_t* module,
sensors_poll_device_1_t** device) {
return module->methods->open(module,
SENSORS_HARDWARE_POLL, (struct hw_device_t**)device);
}
static inline int sensors_close_1(sensors_poll_device_1_t* device) {
return device->common.close(&device->common);
}
아주 오래전에 open method가 호출 된다고 했던거 기억하는지요
이 함수는 아래의 class에서 호출 됩니다
잘 기억이 나지 않는다면 1편을 참조하시기 바랍니다
frameworks/native/services/sensorservice/SensorDevice.cpp
SensorDevice::SensorDevice()
: mSensorDevice(0),
mSensorModule(0)
{
status_t err = hw_get_module(SENSORS_HARDWARE_MODULE_ID,
(hw_module_t const**)&mSensorModule); //HMI에서 정의 했던 SENSORS_HARDWARE_MODULE_ID를 여기서 호출
err = sensors_open_1(&mSensorModule->common, &mSensorDevice); //HMI open method call & get mSensorDevice
if (mSensorDevice) {
sensor_t const* list;
ssize_t count = mSensorModule->get_sensors_list(mSensorModule, &list); //HMI call get_sensors_list
mActivationCount.setCapacity(count);
Info model;
for (size_t i=0 ; i<size_t(count) ; i++) {
mActivationCount.add(list[i].handle, model);
mSensorDevice->activate( //아까 &dev->device.common으로 보냈던거 구조체 형변환 기억하나요?
reinterpret_cast<struct sensors_poll_device_t *>(mSensorDevice),
list[i].handle, 0);
}
}
activate method 처럼 HMI에서 정의한 함수들을 호출한다
activate 호출이 되면 pipe로 wake message가 날아간다 그리고 poll에서 pipe를 확인하고 이벤트를 읽는다
기타 HMI에서 정의 되었던 각종 method들 batch, poll, setDelay 등 모두 SensorDevice.cpp 에서 호출한다
SensorDevice.cpp는 google에서 만드니 우리가 건들 부분은 없고 포팅을 위해서는 Sensors.cpp 이하만 구현 해주면 될 것이다
애초에 디렉토리 이름이 frameworks/native/serivces/services/ 이다
그 이후로 java랑 어떻게 붙냐면 무지막지하게 긴데 그걸 다 묘사할 수도 없고 대충 써보면
SensorService.cpp -> SensorEventQueue.cpp -> android_hardware_SensorManager.cpp -> SystemSensorManager.java
JNI
java와 c++의 교두보 같은 느낌이다
모든 jni 들은 android_hardware_xxxx.cpp 이런식으로 파일명이 붙는다
framework/base/core/jni/android_hardware_SensorManager.cpp
static JNINativeMethod gSystemSensorManagerMethods[] = {
{"nativeClassInit", //java
"()V", //argument, return type
(void*)nativeClassInit }, //c++
{"nativeGetNextSensor",
"(Landroid/hardware/Sensor;I)I",
(void*)nativeGetNextSensor },
};
static void
nativeClassInit (JNIEnv *_env, jclass _this)
{
jclass sensorClass = _env->FindClass("android/hardware/Sensor");
SensorOffsets& sensorOffsets = gSensorOffsets;
sensorOffsets.name = _env->GetFieldID(sensorClass, "mName", "Ljava/lang/String;");
sensorOffsets.vendor = _env->GetFieldID(sensorClass, "mVendor", "Ljava/lang/String;");
sensorOffsets.version = _env->GetFieldID(sensorClass, "mVersion", "I");
...
}
JNINativeMethod 형식으로 이렇게 c++의 함수 이름과 java의 framework api 이름을 매핑시켜 놓는다
int register_android_hardware_SensorManager(JNIEnv *env)
{
jniRegisterNativeMethods(env, "android/hardware/SystemSensorManager",
gSystemSensorManagerMethods, NELEM(gSystemSensorManagerMethods)); //아까 위에서 매핑했던 이름
jniRegisterNativeMethods(env, "android/hardware/SystemSensorManager$BaseEventQueue",
gBaseEventQueueMethods, NELEM(gBaseEventQueueMethods));
FIND_CLASS(gBaseEventQueueClassInfo.clazz, "android/hardware/SystemSensorManager$BaseEventQueue");
...
}
extern "C" int jniRegisterNativeMethods(C_JNIEnv* env, const char* className,
const JNINativeMethod* gMethods, int numMethods)
{
JNIEnv* e = reinterpret_cast<JNIEnv*>(env);
ALOGV("Registering %s's %d native methods...", className, numMethods);
scoped_local_ref<jclass> c(env, findClass(env, className));
if (c.get() == NULL) {
char* msg;
asprintf(&msg, "Native registration unable to find class '%s'; aborting...", className);
e->FatalError(msg);
}
if ((*env)->RegisterNatives(e, c.get(), gMethods, numMethods) < 0) {
char* msg;
asprintf(&msg, "RegisterNatives failed for '%s'; aborting...", className);
e->FatalError(msg);
}
return 0;
}
Android RunTime에 서비스 등록
frameworks/base/core/jni/AndroidRuntime.cpp
#define REG_JNI(name) { name }
struct RegJNIRec {
int (*mProc)(JNIEnv*);
};
static const RegJNIRec gRegJNI[] = {
REG_JNI(register_com_android_internal_os_RuntimeInit),
REG_JNI(register_android_os_SystemClock),
REG_JNI(register_android_util_EventLog),
...
REG_JNI(register_android_hardware_SensorManager), //아까 java method와 c++ method를 연결했던 그 함수 포인터
...
}
extern "C"
jint Java_LoadClass_registerNatives(JNIEnv* env, jclass clazz) {
return register_jni_procs(gRegJNI, NELEM(gRegJNI), env);
}
static int register_jni_procs(const RegJNIRec array[], size_t count, JNIEnv* env)
{
for (size_t i = 0; i < count; i++) {
if (array[i].mProc(env) < 0) {
...
} //mProc 즉 RegJNIRec에 등록된 function pointer들이 실행 된다
int AndroidRuntime::startReg(JNIEnv* env)
{
/*
* This hook causes all future threads created in this process to be
* attached to the JavaVM. (This needs to go away in favor of JNI
* Attach calls.)
*/
androidSetCreateThreadFunc((android_create_thread_fn) javaCreateThreadEtc)
if(register_jni_procs(gRegJNI, NELEM(gRegJNI), env) < 0) {
...
}
부팅하면 ART에 의해 startReg가 호출되고 struct gREGJNI에 들어간 각종 native funtion들은 register_jni_procs에 의해 모두 등록 된다
Java Application
public class MainActivity extends Activity implements SensorEventListener{
private SensorManager mSensorManager;
private Sensor mSensorAccelerometer;
private float[] tGravity;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
mSensorManager = (SensorManager)getSystemService(SENSOR_SERVICE);
List<Sensor> lSensor = mSensorManager.getSensorList(Sensor.TYPE_ALL);
for(int i=0; i<lSensor.size(); i++)
{
Log.d("test@debug", String.format("vendor: %s, name: %s, type: %s",
lSensor.get(i).getVendor(), lSensor.get(i).getName(), lSensor.get(i).getStringType()));
}
mSensorAccelerometer = mSensorManager.getDefaultSensor(Sensor.TYPE_ACCELEROMETER);
}
@Override
protected void onResume() {
super.onResume();
mSensorManager.registerListener(this, mSensorAccelerometer, SensorManager.SENSOR_DELAY_NORMAL);
}
@Override
protected void onPause() {
super.onPause();
mSensorManager.unregisterListener(this);
}
@Override
public void onSensorChanged(SensorEvent event) {
switch(event.sensor.getType()) {
case Sensor.TYPE_ACCELEROMETER:
default:
tGravity = event.values.clone();
}
}
@Override
public void onAccuracyChanged(Sensor sensor, int accuracy) {
}
}
Sensor.java - getType, getVendor, getName등의 method들이 정의 되어 있다
실행 - nexus 5x
vendor: Bosch, name: BMI160 accelerometer, type: android.sensor.accelerometer
vendor: Bosch, name: BMI160 gyroscope, type: android.sensor.gyroscope
vendor: Bosch, name: BMM150 magnetometer, type: android.sensor.magnetic_field
...
vendor: Google, name: Double Tap, type: com.google.sensor.double_tap
vendor: Google, name: Device Orientation, type: android.sensor.device_orientation
framework/base/core/java/android/hardware/SensorManager.java
public boolean registerListener(SensorEventListener listener, Sensor sensor, ...) {
return registerListenerImpl(listener, sensor, ...);
}
onResume(), onPause()에서 호출 되는 registerListener method
frameworks/base/core/java/android/hardware/SystemSensorManager.java
protected boolean registerListenerImpl(SensorEventListener listener, Sensor sensor,...) {
...
Looper looper = (handler != null) ? handler.getLooper() : mMainLooper;
queue = new SensorEventQueue(listener, looper, this);
queue.addSensor(...)
mSensorListeners.put(listener, queue);
...
}
private static abstract class BaseEventQueue {
private static native int nativeEnableSensor(long eventQ, int handle ...)
private long nSensorEventQueue;
BaseEventQueue(Looper looper, SystemSensorManager manager) {
nSensorEventQueue = nativeInitBaseEventQueue(this, looper.getQueue(), mSractch);
...
}
}
static final class SensorEventQueue extends BaseEventQueue {
public SensorEventQueue(SensorEventListener listener, Looper looper,
SystemSensorManager manager) {
super(looper, manager);
mListener = listener;
}
}
looper 없으면 생성하고 SensorEvent Queue 만들고 queue에 센서를 추가한다
public boolean addSensor(
...
addSensorEvent(sensor);
if(enableSensor(...))
)
private int enableSensor(
Sensor sensor, ...) {
return nativeEnableSensor(nSensorEventQueue, ...);
}
static jint nativeEnableSensor(JNIEnv *env, jclass clazz, ...) {
sp<Receiver> receiver(reinterpret_cast<Receiver *>(eventQ));
return receiver->getSensorEventQueue()->enableSensor(handle, ...);
}
다시 JNI로 돌아가서 확인해보면
frameworks/base/core/jni/android_hardware_SensorManager.cpp
static JNINativeMethod gBaseEventQueueMethods[] = {
{"nativeInitBaseEventQueue",
"(Landroid/hardware/SystemSensorManager$BaseEventQueue;Landroid/os/MessageQueue;[F)J",
(void*)nativeInitSensorEventQueue },
{"nativeEnableSensor",
"(JIIII)I",
(void*)nativeEnableSensor },
{"nativeDisableSensor",
"(JI)I",
(void*)nativeDisableSensor },
{"nativeDestroySensorEventQueue",
"(J)V",
(void*)nativeDestroySensorEventQueue },
{"nativeFlushSensor",
"(J)I",
(void*)nativeFlushSensor },
}
java application test code
cts/apps/CtsVerifier/src/com/android/cts/verifier/sensors/HeartRateMonitorTestActivity.java
정리
- SensorManager = onCreate(), (SensorManager)getSystemService(SENSOR_SERVICE); : java sensor application
- SensorManager.getSensorList - getType, getVendor, getName등 method 정의 : Sensor.java
- registerListener - onResume() onPause() : SensorManager.java
- registerListenerImpl - Looper per SensorEvnentListener : SystemSensorManager.java
- static final class SensorEventQueue extends BaseEventQueue : SystemSensorManager.java
addSensor가 호출, 부모의 method가 호출된다 - private static abstract class BaseEventQueue
-> enableSensor -> nativeEnableSensor - static jint nativeEnableSensor - framework/base/core/jni/android_hardware_SensorManager.cpp
- SensorEventQueue::enableSensor - SensorEventQueue.cpp
- enableDiasble - frameworks/native/services/sernsorservice/SensorService.cpp
SensorService::enable - SensorDevice& dev(SensorDevice::getInstance());
singleton 기법으로 instatnce 생성 - SensorDevice.cpp
기타
input keyevent 62
sendevent
sendevent /dev/input/event
getevent
hex 값으로 데이터 가져옴
'devel > android' 카테고리의 다른 글
| Android Sensor HAL Porting Guide? (0) | 2017.03.18 |
|---|---|
| 안드로이드 센서 프레임워크 분석#1 - Android Sensor Service Porting (0) | 2016.12.24 |
| JNI types and Data structures - signatures (0) | 2016.12.07 |
| java nested class jni 의 c로 전달하는 방법 및 java 메서드 호출 (0) | 2015.12.24 |
| android studio 1.5 에서 jni debug 할 때 ldLibs 설정하는 방법 (0) | 2015.12.07 |